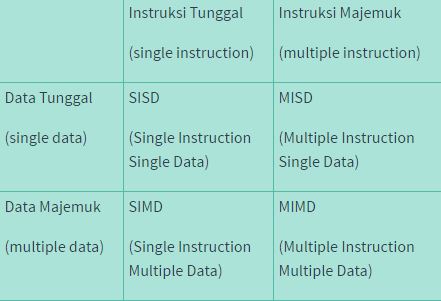
Bioinformatika (bioinformatics) adalah ilmu yang mempelajari penerapan teknik komputasional untuk mengelola dan menganalisis informasi biologis.
Bidang ini mencakup penerapan metode-metode matematika, statistika, informatika, fisika, biologi, dan ilmu kedokteran untuk memecahkan masalah-masalah biologis, terutama dengan menggunakan sekuens DNA dan asam amino serta informasi yang berkaitan dengannya.
Contoh topik utama bidang ini meliputi basis data untuk
mengelola informasi biologis,
penyejajaran sekuens (sequence alignment),
prediksi struktur untuk meramalkan bentuk struktur protein maupun struktur sekunder RNA,
analisis filogenetik, dan
analisis ekspresi gen.
Bioinformatika merupakan ilmu terapan yang lahir dari perkembangan teknologi informasi dibidang molekular. Pembahasan dibidang bioinformatik ini tidak terlepas dari perkembangan biologi molekular modern, salah satunya peningkatan pemahaman manusia dalam bidang genomic yang terdapat dalam molekul DNA.
Kajian baru Bioinformatika ini tak lepas dari perkembangan biologi molekul modern yang ditandai dengan kemampuan manusia untuk memahami genom, yaitu cetak biru informasi genetik yang menentukan sifat setiap makhluk hidup yang disandi dalam bentuk pita molekul DNA (asam deoksiribonukleat). Kemampuan untuk memahami dan memanipulasi kode genetik DNA ini sangat didukung oleh TI melalui perangkat perangkat keras maupun lunak. Hal ini bisa dilihat pada upaya Celera Genomics, perusahaan bioteknologi Amerika Serikat yang melakukan pembacaan sekuen genom manusia yang secara maksimal memanfaatkan TI sehingga bisa melakukan pekerjaannya dalam waktu yang singkat (hanya beberapa tahun), dibanding usaha konsorsium lembaga riset publik AS, Eropa, dan lain-lain, yang memakan waktu lebih dari 10 tahun.
Kelahiran Bioinformatika modern tak lepas dari perkembangan bioteknologi di era tahun 70-an, dimana seorang ilmuwan AS melakukan inovasi dalam mengembangkan teknologi DNA rekombinan. Berkat penemuan ini lahirlah perusahaan bioteknologi pertama di dunia, yaitu Genentech di AS, yang kemudian memproduksi protein hormon insulin dalam bakteri, yang dibutuhkan penderita diabetes. Selama ini insulin hanya bisa didapatkan dalam jumlah sangat terbatas dari organ pankreas sapi.
Bioteknologi modern ditandai dengan kemampuan pada manipulasi DNA. Rantai/sekuen DNA yang mengkode protein disebut gen. Gen ditranskripsikan menjadi mRNA, kemudian mRNA ditranslasikan menjadi protein. Protein sebagai produk akhir bertugas menunjang seluruh proses kehidupan, antara lain sebagai katalis reaksi biokimia dalam tubuh (disebut enzim), berperan serta dalam sistem pertahanan tubuh melawan virus, parasit dan lain-lain (disebut antibodi), menyusun struktur tubuh dari ujung kaki (otot terbentuk dari protein actin, myosin, dan sebagainya) sampai ujung rambut (rambut tersusun dari protein keratin), dan lain-lain. Arus informasi, DNA -> RNA -> Protein, inilah yang disebut sentral dogma dalam biologi molekul.
Sekuen DNA satu organisme, yaitu pada sejenis virus yang memiliki kurang lebih 5.000 nukleotida/molekul DNA atau sekitar 11 gen, berhasil dibaca secara menyeluruh pada tahun 1977. Sekuen seluruh DNA manusia terdiri dari 3 milyar nukleotida yang menyusun 100.000 gen dapat dipetakan dalam waktu 3 tahun. Saat ini terdapat milyaran data nukleotida yang tersimpan dalam database DNA, GenBank di AS yang didirikan tahun 1982. Di Indonesia, ada Lembaga Biologi Molekul Eijkman yang terletak di Jakarta. Di sini kita bisa membaca sekuen sekitar 500 nukleotida hanya dengan membayar $15. Trend yang sama juga nampak pada database lain seperti database sekuen asam amino penyusun protein, database struktur 3D protein, dan sebagainya. Inovasi teknologi DNA chip yang dipelopori oleh perusahaan bioteknologi AS, Affymetrix di Silicon Valley telah mendorong munculnya database baru mengenai RNA. Desakan kebutuhan untuk mengumpulkan, menyimpan dan menganalisa data-data biologis dari database DNA, RNA maupun protein inilah yang semakin memacu perkembangan kajian Bioinformatika.
Manfaat Bioinformatika
- Bioinformatika dalam Bidang Klinis
Bioinformatika dalam bidang klinis sering disebut sebagai informatika klinis (clinical informatics). Aplikasi dari informatika klinis ini berbentuk manajemen data-data klinis dari pasien melalui Electrical Medical Record (EMR) yang dikembangkan oleh Clement J. McDonald dari Indiana University School of Medicine pada tahun 1972. McDonald pertama kali mengaplikasikan EMR pada 33 orang pasien penyakit gula (diabetes). Sekarang EMR ini telah diaplikasikan pada berbagai penyakit. Data yang disimpan meliputi data analisa diagnosa laboratorium, hasil konsultasi dan saran, foto rontgen, ukuran detak jantung, dan lain lain. Dengan data ini dokter akan bisa menentukan obat yang sesuai dengan kondisi pasien tertentu dan lebih jauh lagi, dengan dibacanya genom manusia, akan memungkinkan untuk mengetahui penyakit genetik seseorang, sehingga penanganan terhadap pasien menjadi lebih akurat. - Bioinformatika untuk Identifikasi Agent Penyakit Baru
Bioinformatika juga menyediakan tool yang sangat penting untuk identifikasi agent penyakit yang belum dikenal penyebabnya. Banyak sekali penyakit baru yang muncul dalam dekade ini, dan diantaranya yang masih hangat adalah SARS (Severe Acute Respiratory Syndrome). Pada awalnya, penyakit ini diperkirakan disebabkan oleh virus influenza karena gejalanya mirip dengan gejala pengidap influenza. Akan tetapi ternyata dugaan ini salah karena virus influenza tidak terisolasi dari pasien. Perkirakan lain penyakit ini disebabkan oleh bakteri Candida karena bakteri ini terisolasi dari beberapa pasien. Tapi perkiraan ini juga salah. Akhirnya ditemukan bahwa dari sebagian besar pasien SARS terisolasi virus Corona jika dilihat dari morfologinya. Sekuen genom virus ini kemudian dibaca dan dari hasil analisa dikonfirmasikan bahwa penyebab SARS adalah virus Corona yang telah berubah (mutasi) dari virus Corona yang ada selama ini. Dalam rentetan proses ini, Bioinformatika memegang peranan penting. Pertama pada proses pembacaan genom virus Corona. Karena di database seperti GenBank, EMBL (European Molecular Biology Laboratory), dan DDBJ (DNA Data Bank of Japan) sudah tersedia data sekuen beberapa virus Corona, yang bisa digunakan untuk mendisain primer yang digunakan untuk amplifikasi DNA virus SARS ini. Software untuk mendisain primer juga tersedia, baik yang gratis maupun yang komersial. Contoh yang gratis adalah Webprimer yang disediakan oleh Stanford Genomic Resources (http://genome-www2.stanford.edu/cgi-bin/SGD/web-primer), GeneWalker yang disediakan oleh Cybergene AB http://www.cybergene.se/primerdisain/genewalker), dan lain sebagainya. Untuk yang komersial ada Primer Disainer yang dikembangkan oleh Scientific & Education Software, dan software-software untuk analisa DNA lainnya seperti Sequencher (GeneCodes Corp.), SeqMan II (DNA STAR Inc.), Genetyx (GENETYX Corp.), DNASIS (HITACHI Software), dan lain lain. Kedua pada proses mencari kemiripan sekuen (homology alignment) virus yang didapatkan dengan virus lainnya. Dari hasil analisa virus SARS diketahui bahwa genom virus Corona penyebab SARS berbeda dengan virus Corona lainnya. Perbedaan ini diketahui dengan menggunakan homology alignment dari sekuen virus SARS.
Selanjutnya, Bioinformatika juga berfungsi untuk analisa posisi sejauh mana suatu virus berbeda dengan virus lainnya. - Bioinformatika untuk Diagnosa Penyakit Baru
Untuk menangani penyakit baru diperlukan diagnosa yang akurat sehingga dapat dibedakan dengan penyakit lain. Diagnosa yang akurat ini sangat diperlukan untuk pemberian obat dan perawatan yang tepat bagi pasien. Ada beberapa cara untuk mendiagnosa suatu penyakit, antara lain: isolasi agent penyebab penyakit tersebut dan analisa morfologinya, deteksi antibodi yang dihasilkan dari infeksi dengan teknik enzyme-linked immunosorbent assay (ELISA), dan deteksi gen dari agent pembawa penyakit tersebut dengan Polymerase Chain Reaction (PCR). Teknik yang banyak dan lazim dipakai saat ini adalah teknik PCR. Teknik ini sederhana, praktis dan cepat. Yang penting dalam teknik PCR adalah disain primer untuk amplifikasi DNA, yang memerlukan data sekuen dari genom agent yang bersangkutan dan software seperti yang telah diuraikan di atas. Disinilah Bioinformatika memainkan peranannya. Untuk agent yang mempunyai genom RNA, harus dilakukan reverse transcription (proses sintesa DNA dari RNA) terlebih dahulu dengan menggunakan enzim reverse transcriptase. Setelah DNA diperoleh baru dilakukan PCR. Reverse transcription dan PCR ini bisa dilakukan sekaligus dan biasanya dinamakan RT-PCR. Teknik PCR ini bersifat kualitatif, oleh sebab itu sejak beberapa tahun yang lalu dikembangkan teknik lain, yaitu Real Time PCR yang bersifat kuantitatif. Dari hasil Real Time PCR ini bisa ditentukan kuantitas suatu agent di dalam tubuh seseorang, sehingga bisa dievaluasi tingkat emergensinya. Pada Real Time PCR ini selain primer diperlukan probe yang harus didisain sesuai dengan sekuen agent yang bersangkutan. Di sini juga diperlukan software atau program Bioinformatika. - Bioinformatika untuk Penemuan Obat
Cara untuk menemukan obat biasanya dilakukan dengan menemukan zat/senyawa yang dapat menekan perkembangbiakan suatu agent penyebab penyakit. Karena perkembangbiakan agent tersebut dipengaruhi oleh banyak faktor, maka faktor-faktor inilah yang dijadikan target. Diantaranya adalah enzim-enzim yang diperlukan untuk perkembangbiakan suatu agent Mula-mula yang harus dilakukan adalah analisa struktur dan fungsi enzim-enzim tersebut. Kemudian mencari atau mensintesa zat/senyawa yang dapat menekan fungsi dari enzim-enzim tersebut. Analisa struktur dan fungsi enzim ini dilakukan dengan cara mengganti asam amino tertentu dan menguji efeknya. Analisa penggantian asam amino ini dahulu dilakukan secara random sehingga memerlukan waktu yang lama. Setelah Bioinformatika berkembang, data-data protein yang sudah dianalisa bebas diakses oleh siapapun, baik data sekuen asam amino-nya seperti yang ada di SWISS-PROT (http://www.ebi.ac.uk/swissprot/) maupun struktur 3D-nya yang tersedia di Protein Data Bank (PDB) (http://www.rcsb.org/pdb/). Dengan database yang tersedia ini, enzim yang baru ditemukan dapat dibandingkan sekuen asam amino-nya, sehingga bisa diperkirakan asam amino yang berperan untuk aktivitas (active site) dan kestabilan enzim tersebut. Setelah asam amino yang berperan sebagai active site dan kestabilan enzim tersebut ditemukan, kemudian dicari atau disintesa senyawa yang dapat berinteraksi dengan asam amino tersebut. Dengan data yang ada di PDB, maka dapat dilihat struktur 3D suatu enzim termasuk active site-nya, sehingga bisa diperkirakan bentuk senyawa yang akan berinteraksi dengan active site tersebut. Dengan demikian, kita cukup mensintesa senyawa yang diperkirakan akan berinteraksi, sehingga obat terhadap suatu penyakit akan jauh lebih cepat ditemukan. Cara ini dinamakan “docking” dan telah banyak digunakan oleh perusahaan farmasi untuk penemuan obat baru. Meskipun dengan Bioinformatika ini dapat diperkirakan senyawa yang berinteraksi dan menekan fungsi suatu enzim, namun hasilnya harus dikonfirmasi dahulu melalui eksperimen di laboratorium. Akan tetapi dengan Bioinformatika, semua proses ini bisa dilakukan lebih cepat sehingga lebih efisien baik dari segi waktu maupun finansial. Tahun 1997, Ian Wilmut dari Roslin Institute dan PPL Therapeutics Ltd, Edinburgh, Skotlandia, berhasil mengklon gen manusia yang menghasilkan faktor IX (faktor pembekuan darah), dan memasukkan ke kromosom biri-biri. Diharapkan biri-biri yang selnya mengandung gen manusia faktor IX akan menghasilkan susu yang mengandung faktor pembekuan darah. Jika berhasil diproduksi dalam jumlah banyak maka faktor IX yang diisolasi dari susu harganya bisa lebih murah untuk membantu para penderita hemofilia.Pengertian secara Khusus
Pada bagian pendahuluan kita telah diberikan gambaran sekilas mengenai perkembangan dan apa yang dapat diberikan oleh Bioinformatika. Bagian berikut ini akan membahas lebih detail tentang Bioinformatika. Secara umum, Bioinformatika dapat digambarkan sebagai: segala bentuk penggunaan komputer dalam menangani informasi-informasi biologi. Dalam prakteknya, definisi yang digunakan oleh kebanyakan orang bersifat lebih terperinci. Bioinformatika menurut kebanyakan orang adalah satu sinonim dari komputasi biologi molekul (penggunaan komputer dalam menandai karakterisasi dari komponenkomponen molekul dari makhluk hidup). - Bioinformatika “klasik”
Sebagian besar ahli Biologi mengistilahkan ‘mereka sedang melakukan Bioinformatika’ ketika mereka sedang menggunakan komputer untuk menyimpan, melihat atau mengambil data, menganalisa atau memprediksi komposisi atau struktur dari biomolekul. Ketika kemampuan komputer menjadi semakin tinggi maka proses yang dilakukan dalam Bioinformatika dapat ditambah dengan melakukan simulasi. Yang termasuk biomolekul diantaranya adalah materi genetik dari manusia –asam nukleat– dan produk dari gen manusia, yaitu protein. Hal-hal diataslah yang merupakan bahasan utama dari Bioinformatika “klasik”, terutama berurusan dengan analisis sekuen (sequence analysis).Definisi Bioinformatika menurut Fredj Tekaia dari Institut Pasteur [TEKAIA2004] adalah: “metode matematika, statistik dan komputasi yang bertujuan untuk menyelesaikan masalah-masalah biologi dengan menggunakan sekuen DNA dan asam amino dan informasi-informasi yang terkait dengannya.” Dari sudut pandang Matematika, sebagian besar molekul biologi mempunyai sifat yang menarik, yaitu molekul-molekul tersebut adalah polymer; rantai-rantai yang tersusun rapi dari modul-modul molekul yang lebih sederhana, yang disebut monomer. Monomer dapat dianalogikan sebagai bagian dari bangunan, dimana meskipun bagianbagian tersebut berbeda warna dan bentuk, namun semua memiliki ketebalan yang sama dan cara yang sama untuk dihubungkan antara yang satu dengan yang lain. Monomer yang dapat dikombinasi dalam satu rantai ada dalam satu kelas umum yang sama, namun tiap jenis monomer dalam kelas tersebut mempunyai karakteristik masing-masing yang terdefinisi dengan baik. Beberapa molekul-molekul monomer dapat digabungkan bersama membentuk sebuah entitas yang berukuran lebih besar, yang disebut macromolecule. Macromolecule dapat mempunyai informasi isi tertentu yang menarik dan sifat-sifat kimia tertentu. Berdasarkan skema di atas, monomer-monomer tertentu dalam macromolecule
dari DNA dapat diperlakukan secara komputasi sebagai huruf-huruf dari alfabet, yang diletakkan dalam sebuah aturan yang telah diprogram sebelumnya untuk membawa pesan atau melakukan kerja di dalam sel.
Proses yang diterangkan di atas terjadi pada tingkat molekul di dalam sel. Salah
satu cara untuk mempelajari proses tersebut selain dengan mengamati dalam
laboratorium biologi yang sangat khusus adalah dengan menggunakan Bioinformatika sesuai dengan definisi “klasik” yang telah disebutkan di atas.
Bioinformatika “baru”
Salah satu pencapaian besar dalam metode Bioinformatika adalah selesainya
proyek pemetaan genom manusia (Human Genome Project). Selesainya proyek raksasa tersebut menyebabkan bentuk dan prioritas dari riset dan penerapan Bioinformatika berubah. Secara umum dapat dikatakan bahwa proyek tersebut membawa perubahan besar pada sistem hidup kita, sehingga sering disebutkan –terutama oleh ahli biologi– bahwa kita saat ini berada di masa pascagenom.
Selesainya proyek pemetaan genom manusia ini membawa beberapa perubahan
bagi Bioinformatika, diantaranya:
Setelah memiliki beberapa genom yang utuh maka kita dapat mencari perbedaan
dan persamaan di antara gen-gen dari spesies yang berbeda. Dari studi perbandingan
antara gen-gen tersebut dapat ditarik kesimpulan tertentu mengenai spesies-spesies dan secara umum mengenai evolusi. Jenis cabang ilmu ini sering disebut sebagai perbandingan genom (comparative genomics).
Sekarang ada teknologi yang didisain untuk mengukur jumlah relatif dari
kopi/cetakan sebuah pesan genetik (level dari ekspresi genetik) pada beberapa tingkatan yang berbeda pada perkembangan atau penyakit atau pada jaringan yang berbeda.Teknologi tersebut, contohnya seperti DNA microarrays akan semakin penting. Akibat yang lain, secara langsung, adalah cara dalam skala besar untuk mengidentifikasi fungsi-fungsi dan keterkaitan dari gen (contohnya metode yeast twohybrid) akan semakin tumbuh secara signifikan dan bersamanya akan mengikuti Bioinformatika yang berkaitan langsung dengan kerja fungsi genom (functional genomics). Akan ada perubahan besar dalam penekanan dari gen itu sendiri ke hasil-hasil dari gen. Yang pada akhirnya akan menuntun ke: usaha untuk mengkatalogkan semua aktivitas dan karakteristik interaksi antara semua hasil-hasil dari gen (pada manusia) yang disebut proteomics; usaha untuk mengkristalisasi dan memprediksikan struktur-struktur dari semua protein (pada manusia) yang disebut structural genomics. Apa yang disebut orang sebagai research informatics atau medical informatics, manajemen dari semua data eksperimen biomedik yang berkaitan dengan molekul atau pasien tertentu –mulai dari spektroskop massal, hingga ke efek samping klinis– akan berubah dari semula hanya merupakan kepentingan bagi mereka yang bekerja di perusahaan obat-obatan dan bagian TI Rumah Sakit akan menjadi jalur utama dari biologi molekul dan biologi sel, dan berubah jalur dari komersial dan klinikal ke arah akademis. Dari uraian di atas terlihat bahwa Bioinformatika sangat mempengaruhi kehidupan manusia, terutama untuk mencapai kehidupan yang lebih baik. Penggunaan komputer yang notabene merupakan salah satu keahlian utama dari orang yang bergerak dalam TI merupakan salah satu unsur utama dalam Bioinformatika, baik dalam Bioinformatika “klasik” maupun Bioinformatika “baru”.
Berikut ini adalah bidang bidang yang terkait Bioinformatika
Dari pengertian Bioinformatika baik yang klasik maupun baru, terlihat banyak
terdapat cabang-cabang disiplin ilmu yang terkait dengan Bioinformatika –terutama
karena Bioinformatika itu sendiri merupakan suatu bidang interdisipliner–. Hal tersebut
menimbulkan banyak pilihan bagi orang yang ingin mendalami Bioinformatika. Di
bawah ini akan disebutkan beberapa bidang yang terkait dengan Bioinformatika.
- Biophysics
Biologi molekul sendiri merupakan pengembangan yang lahir dari biophysics. Biophysics adalah sebuah bidang interdisipliner yang mengaplikasikan teknik-teknik dari ilmu Fisika untuk memahami struktur dan fungsi biologi (British Biophysical Society). Sesuai dengan definisi di atas, bidang ini merupakan suatu bidang yang luas. Namun secara langsung disiplin ilmu ini terkait dengan Bioinformatika karena penggunaan teknik-teknik dari ilmu Fisika untuk memahami struktur membutuhkan penggunaan TI. - Computational Biology
Computational biology merupakan bagian dari Bioinformatika (dalam arti yang paling luas) yang paling dekat dengan bidang Biologi umum klasik. Fokus dari computational biology adalah gerak evolusi, populasi, dan biologi teoritis daripada biomedis dalam molekul dan sel. Tak dapat dielakkan bahwa Biologi Molekul cukup penting dalam computational biology, namun itu bukanlah inti dari disiplin ilmu ini. Pada penerapan computational biology, model-model statistika untuk fenomena biologi lebih disukai dipakai dibandingkan dengan model sebenarnya. Dalam beberapa hal cara tersebut cukup baik mengingat pada kasus tertentu eksperimen langsung pada fenomena biologi cukup sulit. Tidak semua dari computational biology merupakan Bioinformatika, seperti contohnya Model Matematika bukan merupakan Bioinformatika, bahkan meskipun dikaitkan dengan masalah biologi. - Medical Informatics
Menurut Aamir Zakaria [ZAKARIA2004] Pengertian dari medical informatics adalah “sebuah disiplin ilmu yang baru yang didefinisikan sebagai pembelajaran, penemuan, dan implementasi dari struktur dan algoritma untuk meningkatkan komunikasi, pengertian dan manajemen informasi medis.” Medical informatics lebih memperhatikan struktur dan algoritma untuk pengolahan data medis, dibandingkan dengan data itu sendiri. Disiplin ilmu ini, untuk alasan praktis, kemungkinan besar berkaitan dengan data-data yang didapatkan pada level biologi yang lebih “rumit” –yaitu informasi dari sistem-sistem superselular, tepat pada level populasi—di mana sebagian besar dari Bioinformatika lebih memperhatikan informasi dari sistem dan struktur biomolekul dan selular. - Cheminformatics
Cheminformatics adalah kombinasi dari sintesis kimia, penyaringan biologis, dan pendekatan data-mining yang digunakan untuk penemuan dan pengembangan obat (Cambridge Healthech Institute’s Sixth Annual Cheminformatics conference). Pengertian disiplin ilmu yang disebutkan di atas lebih merupakan identifikasi dari salah satu aktivitas yang paling populer dibandingkan dengan berbagai bidang studi yang mungkin ada di bawah bidang ini. Salah satu contoh penemuan obat yang paling sukses sepanjang sejarah adalah penisilin, dapat menggambarkan cara untuk menemukan dan mengembangkan obatobatan hingga sekarang –meskipun terlihat aneh–. Cara untuk menemukan dan mengembangkan obat adalah hasil dari kesempatan, observasi, dan banyak proses kimia yang intensif dan lambat. Sampai beberapa waktu yang lalu, disain obat dianggap harus selalu menggunakan kerja yang intensif, proses uji dan gagal (trial-error process). Kemungkinan penggunaan TI untuk merencanakan secara cerdas dan dengan mengotomatiskan proses-proses yang terkait dengan sintesis kimiawi dari komponenkomponen pengobatan merupakan suatu prospek yang sangat menarik bagi ahli kimia dan ahli biokimia. Penghargaan untuk menghasilkan obat yang dapat dipasarkan secara lebih cepat sangatlah besar, sehingga target inilah yang merupakan inti dari cheminformatics. Ruang lingkup akademis dari cheminformatics ini sangat luas. Contoh bidang minatnya antara lain: Synthesis Planning, Reaction and Structure Retrieval, 3-D Structure Retrieval, Modelling, Computational Chemistry, Visualisation Tools and Utilities. - Genomics
Genomics adalah bidang ilmu yang ada sebelum selesainya sekuen genom, kecuali dalam bentuk yang paling kasar. Genomics adalah setiap usaha untuk menganalisa atau membandingkan seluruh komplemen genetik dari satu spesies atau lebih. Secara logis tentu saja mungkin untuk membandingkan genom-genom dengan membandingkan kurang lebih suatu himpunan bagian dari gen di dalam genom yang representatif. - Mathematical Biology
Mathematical biology lebih mudah dibedakan dengan Bioinformatika daripada computational biology dengan Bioinformatika. Mathematical biology juga menangani masalah-masalah biologi, namun metode yang digunakan untuk menangani masalah tersebut tidak perlu secara numerik dan tidak perlu diimplementasikan dalam software maupun hardware. Bahkan metode yang dipakai tidak perlu “menyelesaikan” masalah apapun; dalam mathematical biology bisa dianggap beralasan untuk mempublikasikan sebuah hasil yang hanya menyatakan bahwa suatu masalah biologi berada pada kelas umum tertentu. Menurut Alex Kasman [KASMAN2004] Secara umum mathematical biology melingkupi semua ketertarikan teoritis yang tidak perlu merupakan sesuatu yang beralgoritma, dan tidak perlu dalam bentuk molekul, dan tidak perlu berguna dalam menganalisis data yang terkumpul. - Proteomics
Istilah proteomics pertama kali digunakan untuk menggambarkan himpunan dari protein-protein yang tersusun (encoded) oleh genom. Ilmu yang mempelajari proteome, yang disebut proteomics, pada saat ini tidak hanya memperhatikan semua protein di dalam sel yang diberikan, tetapi juga himpunan dari semua bentuk isoform dan modifikasi dari semua protein, interaksi diantaranya, deskripsi struktural dari proteinprotein dan kompleks-kompleks orde tingkat tinggi dari protein, dan mengenai masalah tersebut hampir semua pasca genom. Michael J. Dunn [DUNN2004], Pemimpin Redaksi dari Proteomics mendefiniskan kata “proteome” sebagai: “The PROTEin complement of the genOME”. Dan mendefinisikan proteomics berkaitan dengan: “studi kuantitatif dan kualitatif dari ekspresi gen di level dari protein-protein fungsional itu sendiri”. Yaitu: “sebuah antarmuka antara biokimia protein dengan biologi molekul”. Mengkarakterisasi sebanyak puluhan ribu protein-protein yang dinyatakan dalam sebuah tipe sel yang diberikan pada waktu tertentu –apakah untuk mengukur berat molekul atau nilai-nilai isoelektrik protein-protein tersebut– melibatkan tempat penyimpanan dan perbandingan dari data yang memiliki jumlah yang sangat besar, tak terhindarkan lagi akan memerlukan Bioinformatika. - Pharmacogenomics
Pharmacogenomics adalah aplikasi dari pendekatan genomik dan teknologi pada identifikasi dari target-target obat. Contohnya meliputi menjaring semua genom untuk penerima yang potensial dengan menggunakan cara Bioinformatika, atau dengan menyelidiki bentuk pola dari ekspresi gen di dalam baik patogen maupun induk selama terjadinya infeksi, atau maupun dengan memeriksa karakteristik pola-pola ekspresi yang ditemukan dalam tumor atau contoh dari pasien untuk kepentingan diagnosa (kemungkinan untuk mengejar target potensial terapi kanker). Istilah pharmacogenomics digunakan lebih untuk urusan yang lebih “trivial” — tetapi dapat diargumentasikan lebih berguna– dari aplikasi pendekatan Bioinformatika pada pengkatalogan dan pemrosesan informasi yang berkaitan dengan ilmu Farmasi dan Genetika, untuk contohnya adalah pengumpulan informasi pasien dalam database. - Pharmacogenetics
Tiap individu mempunyai respon yang berbeda-beda terhadap berbagai pengaruh
obat; sebagian ada yang positif, sebagian ada yang sedikit perubahan yang tampak pada kondisi mereka dan ada juga yang mendapatkan efek samping atau reaksi alergi. Sebagian dari reaksi-reaksi ini diketahui mempunyai dasar genetik. Pharmacogenetics adalah bagian dari pharmacogenomics yang menggunakan metode genomik/Bioinformatika untuk mengidentifikasi hubungan-hubungan genomik, contohnya SNP (Single Nucleotide Polymorphisms), karakteristik dari profil respons pasien tertentu dan menggunakan informasi-informasi tersebut untuk memberitahu administrasi dan pengembangan terapi pengobatan. Secara menakjubkan pendekatan tersebut telah digunakan untuk “menghidupkan kembali” obat-obatan yang sebelumnya dianggap tidak efektif, namun ternyata diketahui manjur pada sekelompok pasien tertentu. Disiplin ilmu ini juga dapat digunakan untuk mengoptimalkan dosis kemoterapi pada pasien-pasien tertentu.
Gambaran dari sebagian bidang-bidang yang terkait dengan Bioinformatika di
atas memperlihatkan bahwa Bioinformatika mempunyai ruang lingkup yang sangat luas dan mempunyai peran yang sangat besar dalam bidangnya. Bahkan pada bidang
pelayanan kesehatan Bioinformatika menimbulkan disiplin ilmu baru yang menyebabkan peningkatan pelayanan kesehatanTEKNOLOGI DAN PENERAPAN BIOINFORMATIKA
1. Program-program Bioinformatika
Sehari-harinya bionformatika dikerjakan dengan menggunakan program pencari sekuen (sequence search) seperti BLAST, program analisa sekuen (sequence analysis) seperti EMBOSS dan paket Staden, program prediksi struktur seperti THREADER atau PHD atau program imaging/modelling seperti RasMol dan WHATIF. Contoh-contoh di atas memperlihatkan bahwa telah banyak program pendukung yang mudah di akses dan dipelajari untuk menggunakan Bioinformatika
2. Teknologi Bioinformatika Secara Umum
Pada saat ini banyak pekerjaan Bioinformatika berkaitan dengan teknologi database. Penggunaan database ini meliputi baik tempat penyimpanan database “umum” seperti GenBank atau PDB maupun database “pribadi”, seperti yang digunakan oleh grup riset yang terlibat dalam proyek pemetaan gen atau database yang dimiliki oleh perusahaan-perusahaan bioteknologi. Konsumen dari data Bioinformatika menggunakan platform jenis komputer dalam kisaran: mulai dari mesin UNIX yang lebih canggih dan kuat yang dimiliki oleh pengembang dan kolektor hingga ke mesin Mac yang lebih bersahabat yang sering ditemukan menempati laboratorium ahli biologi yang tidak suka komputer. Database dari sekuen data yang ada dapat digunakan untuk mengidentifikasi homolog pada molekul baru yang telah dikuatkan dan disekuenkan di laboratorium. Dari satu nenek moyang mempunyai sifat-sifat yang sama, atau homology, dapat menjadi indikator yang sangat kuat di dalam Bioinformatika. Setelah informasi dari database diperoleh, langkah berikutnya adalah menganalisa data. Pencarian database umumnya berdasarkan pada hasil alignment / pensejajaran sekuen, baik sekuen DNA maupun protein. Kegunaan dari pencarian ini adalah ketika mendapatkan suatu sekuen DNA/protein yang belum diketahui fungsinya maka dengan membandingkannya dengan yang ada dalam database bisa diperkirakan fungsi daripadanya. Salah satu perangkat lunak pencari database yang paling berhasil dan bisa dikatakan menjadi standar sekarang adalah BLAST (Basic Local Alignment Search Tool) yang merupakan program pencarian kesamaan yang didisain untuk mengeksplorasi semua database sekuen yang diminta, baik itu berupa DNA atau protein. Program BLAST juga dapat digunakan untuk mendeteksi hubungan di antara sekuen yang hanya berbagi daerah tertentu yang memiliki kesamaan. Di bawah ini diberikan contoh beberapa alamat situs yang berguna untuk bidang biologi molekul dan genetika:
Data yang memerlukan analisa Bioinformatika dan mendapat banyak perhatian saat ini adalah data hasil DNA chip. Dengan perangkat ini dapat diketahui kuantitas dan kualitas transkripsi satu gen sehingga bisa menunjukkan gen-gen apa saja yang aktif terhadap perlakuan tertentu, misalnya timbulnya kanker, dan lain-lain
Sumber: